第229期方班学术研讨厅成功举办
2026 年6月10日 18:00-21:30,第229期方班学术研讨厅在黄埔研究生院B2栋成功举办。广州大学网络空间安全学院名誉院长方滨兴老师,主点评孔志印老师,胡事民老师,王恩东老师,梅宏老师,黑新宏老师,李建新老师,李舟军老师,李凤华老师。副点评卢璨老师,陈艳利老师,吴昊天老师,唐可可老师,张帆老师,欧阳典老师,张登辉老师,张鹏老师全程参与了课堂的教学,并对同学们的报告逐一进行了指导点评。同时参与的还有网络空间安全学院的部分老师,广州大学方班八期的252名学生。本次研讨厅分为八个小组进行。第一组汇报的同学有江晴柔、刘道铭、潘子睿、熊传恒;第二组汇报的同学有陈梓铭、邓宇航、付翔、黄易;第三组汇报的同学有江宇、吴俊霖、郝怡琛、区文灏;第四组汇报的同学有陈泽涛、罗志松、夏宇飞、关胜圆;第五组汇报的同学有饶智创、黄宏昆、王懿轩、赵耀鹏;第六组汇报的同学有陈泉、单宇宸、黄志豪、王嘉璐;第七组汇报的同学有李国瑞、韦玉娟、黄子杰、张济民;第八组汇报的同学有李小鑫、刘瑛琪、王柏涛、王博文。
第一组
第一位报告人:【江晴柔】
报告题目:【LLM4DistReconfig:配电网重构的微调大型语言模型】
点评老师的意见与建议:
1、需进一步说明大模型用于配电网重构的必要性,重点比较其相较GNN、普通深度学习和专用优化程序的优势。
2、应结合实际业务场景分析配电网高频重构需求是否真实存在,以及大模型推理速度、可靠性是否满足运行要求。
3、建议明确大模型与传统优化算法的分工边界,思考“模型生成候选、传统算法筛选”及其反向流程的可行性。

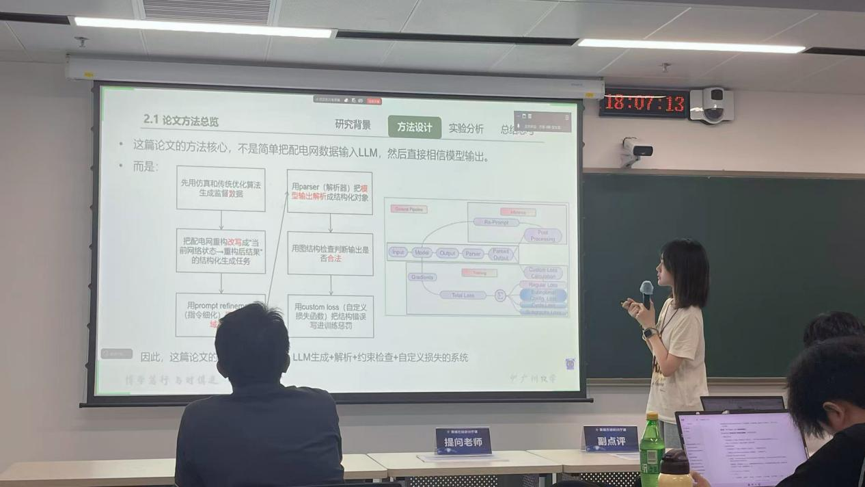
第二位报告人:【刘道铭】
报告题目:【面向大语言模型异构联邦学习的拆分与重要性感知更新机制】
点评老师的意见与建议:
1、英文题目中可能遗漏了 “Splitting” 这一关键部分,同时中文翻译没有准确体现拆分与重要性感知更新之间的关系,建议进一步斟酌题目表述。
2、对论文核心机制提出质疑,认为报告中将 consensus 和 divergence 分成两个相对独立的部分,但现实中二者可能并非完全正交,可能存在既具有共识性又具有分歧性的更新,因此需要进一步思考该方法如何处理这种复杂情况。


第三位报告人:【潘子睿】
报告题目:【Towards Effective and Efficient Continual Pre-training of Large Language Models】
点评老师的意见与建议:
1、需加强小模型代理实验与大模型迁移关系的论证。
2、需补充主题分类器性能评估,说明其对结论的影响。
3、需深入解释灾难性遗忘机制,并明确英文能力评价指标。


第四位报告人:【熊传恒】
报告题目:【New Framework of Robust Image Encryption】
点评老师的意见与建议:
1、同学第一个我推荐你一篇论文就是做水印的加水印的一篇论文叫 cycle gan 我不知道你看过那篇论文没有?
2、你觉得这篇论文有啥问题没?
3、你什么 K 就这个图里面 K 产生随机造成 N?加密和解密的时候产生的 N 是一样的吗?
4、没有 K 的话,在解密端是无法解密出来的吗?


第二组
第一位报告人:【陈梓铭】
报告题目:【PrivCode:当代码生成遇上差分隐私】
点评老师的意见与建议:
1、整体汇报语速偏快,建议在讲解 “两阶段进化式框架”“PrivSA 模块算法流程” 等复杂技术逻辑时适当放慢节奏、增加留白。
2、建议进一步明确 PrivCode 相较于传统 DP-SGD 微调、掩码式两阶段 DP 微调等现有方案的核心创新壁垒。
3、针对 PrivSA 模块与双重过滤机制的核心设计,建议将 “动态权重 λ 的指数衰减系数取值依据”“往返验证中 BERTScore 阈值 0.88 的设定逻辑” 作为高光细节抛出。


第二位报告人:【邓宇航】
报告题目:【Imagine and Seek:利用想象代理改进组合图像检索】
点评老师的意见与建议:
1、这篇论文提出这个方法的出发点是什么,为什么不直接将图文转化为向量,多思考关键问题。
2、论文的超参数部分对于代理图像的设定上存在一定的问题,比如代理图像的数量以及特征向量的融合。
3、多关注论文的背景部分,比如相关工作、现有的方法。分析论文时重点研究论文的主要创新点。


第三位报告人:【付翔】
报告题目:【基于模拟软件过程模型的智能体代码生成研究】
点评老师的意见与建议:
1、指出多智能体系统核心瓶颈是单个智能体输出质量,建议采用多组智能体并行择优的优化思路。
2、认可论文学术价值,建议探索人机协同的最佳介入节点,实现人机优势互补。
3、建议根据不同开发环节匹配适配模型,优化系统容错机制与整体稳定性。


第四位报告人:【黄易】
报告题目:【基于视觉干扰的多模态大语言模型越狱攻击研究】
点评老师的意见与建议:
1、理论深度不足:文章主要围绕“分心假说”开展实验,缺少对“注意力分散”的量化分析(如热力图、权重激活),理论支撑较弱。
2、适用场景有限:攻击方式仅对端到端MLLM有效,无法应对当前多智能体工程中的任务拆分与分步处理范式,实际工程场景下攻击失效。
3、评估指标单一:仅采用攻击成功率,未评估模型输出与原始问题的相关性,建议补充内容相关性指标,验证越狱结果的有效性。


第三组
第一位报告人:【江宇】
报告题目:【ByteScale:在16384块GPU上高效训练2048K上下文大语言模型】
点评老师的意见与建议:
1、整体讲述清楚顺畅,但第一部分讲完存在的问题之后,没有直接转入"作者是如何针对问题提出解决方法的",而是按 PPT 原有顺序进入第二部分。如果在讲完痛点的瞬间就明确告诉听众后面方案要解决的就是这些问题,承接会更紧、效果会更好。
2、实验部分的细节交代不够清楚,网络拓扑、GPU 型号、各对照组的优化方法这些都没有说明白,听众没办法在脑子里重建出作者的实验场景,导致后面的结果数字含金量难以判断。


第二位报告人:【吴俊霖】
报告题目:【FuseLink:利用机内互联与内存重映射构建跨多网卡的高效GPU通信】
点评老师的意见与建议:
1、在相关工作方面,可以讲的更详细一点,比如怎么提到资源的利用率。
2、背景部分可以补充多一点,让听的同学更容易理解。
3、在消融实验部分,可以多讲讲为什么能达到这种效果。


第三位报告人:【郝怡琛】
报告题目:【ZipServ:借助硬件感知无损压缩实现快速且节省内存的大语言模型推理】
点评老师的意见与建议:
1、在多模态的大模型上,BF16是否有相同的数据特征分布。通过实验证明也是有的。
2、在压缩率上需要额外进行一些讨论,能够运行一个更大的模型也是一个值得探究的方向。
3、性能上的优化具体来源于哪里。来源于压缩减少数据规模,所带来的内存贷款的节省。


第四位报告人:【区文灏】
报告题目:【T-MAC:面向边缘低比特大模型部署的基于查表机制的CPU革新方案】
点评老师的意见与建议:
1、T-MAC主要优化了计算,但是没有优化矩阵在内存、寄存器之间传输的过程,但是对于decode阶段访存才是瓶颈
2、背景介绍部分,需要补充优化mpGEMM的相关工作,分析现有方法的优缺点
3、论文主要研究了权重量化模型在边缘设备上的部署,但是没有分析测试所用设备承载全精度模型的能力上限。


第四组
第一位报告人:【陈泽涛】
报告题目:【任意深度对齐: 解锁大语言模型对任意深度的固有安全对齐】
点评老师的意见与建议:
1、研究背景需先定义攻防场景,应先解释越狱攻击、深度预填充攻击的现实条件,再引出防御问题。
2、问题动机要用例子支撑,不要直接给结论,应通过具体案例说明现有防御为何在生成中途失效。
3、实验对开销分析不仅看延迟,也要讨论额外 GPU 资源、探针训练成本和复现可信度。
4、未来如果探究多模态安全不能简单平移文本机制。


第二位报告人:【罗志松】
报告题目:【GIGPO:面向大语言模型智能体训练的组内分组策略优化】
点评老师的意见与建议:
1.介绍方法部分所用时间过少,应增加方法部分的讲解时间;
2、汇报时没有很好将大语言模型智能体与强化学习进行关联;
3、介绍方法时,最主要的方法可以用多几页PPT来介绍。


第三位报告人:【夏宇飞】
报告题目:【AtomicVLA:释放机器人原子技能学习的潜力】
点评老师的意见与建议:
1、整体讲的比较好,方法第二点可以用一个动画表示更清晰。
2、机器人是一个比较复杂的系统,很多细节要讲完确实时间不够。
3、应该要在着重提一下训练的输入和输出。


第四位报告人:【关胜圆】
报告题目:【MemAgent:用强化学习重塑大模型记忆】
点评老师的意见与建议:
1、模型记忆更新与强化学习训练均采用隐变量设计,过程缺乏直观逻辑,建议提升训练可解释性,明确每一步训练行为的作用。
2、目前模型使用固定记忆长度,适配场景受限,建议研究自适应记忆机制,根据文本特征动态调整记忆的容量大小。
3、将拓展多模态作为未来方向存在较大不确定性,论文核心聚焦长上下文任务,后续研究应优先围绕主线任务推进


第五组
第一位报告人:【饶智创】
报告题目:【DST-Mamba:用于长期交通预测的分解时空Mamba】
点评老师的意见与建议:
1、车流量预测是一个很经典的问题,在这个问题上重点在于怎么去捕捉时空依赖性,不管之前的rnn和gnn,还是transformer还是mamba,其实都是在干这个事情。
2、对于未来的发展,关于动态矩阵和动态分解数据是一个应对交通流中突发情况的有效手段。
3、前置时序分解模块:将交通流量拆分为趋势项(低频长期演化)、季节周期项(日 / 周周期性)、残差扰动项(拥堵、事故突发)。


第二位报告人:【黄宏昆】
报告题目:【STARDIS:面向卫星入侵检测系统部署的战略调度与欺骗性信号设计】
点评老师的意见与建议:
1、STAR和DIS的优化目标是什么?如何优化的?优化效果如何?这三个问题是叙事的主结构,你在讲的时候没有说清楚,导致它们的难点没有突出来。
2、PPT文字太多了,要熵减,多用图片表达。
3、卫星场景应该多用相关图片或动画表达,然后在容易出问题的地方指出来进而引入论文的问题和观点,这样就更形象。
方老师点评:
1、什么是欺骗?STAR调度的是什么?你的回答很清楚,说明对论文理解够了,回答质疑或问题时自信点。
2、你对这篇论文有什么疑问吗?对论文的神秘感要祛魅,有时候越玄乎的论文猫腻越大。


第三位报告人:【王懿轩】
报告题目:【一种基于树的工业控制系统安全评估方案】
点评老师的意见与建议:
1、树的连接条件一定是相同工业过程吗 在其他工业流程中也一定是树结构?存在图结构吗?
2、safety和security两侧一定是并行的吗?应该存在相互影响、制约的关系?
3、对于ft树,底层节点就是物理故障?应该进行细分,哪些漏洞导致故障,要细化到故障发生原因。


第四位报告人:【赵耀鹏】
报告题目:【赵耀鹏-Doctor-R1:基于经验式智能体强化学习的临床问诊与推理框架】
点评老师的意见与建议:
1、老师指出:本文需要进一步思考其核心价值究竟在于“融入更多医疗知识”,还是像作者所做的那样,通过强化学习优化医生智能体的问诊策略。相比单纯增加医学知识,动态问诊能力是否具有更强的实际意义,需要进一步分析。
2、老师提出:真实临床中医生往往并不会仅依赖患者语言描述进行诊断,而是会快速结合化验、影像、检查结果等客观信息。因此,论文主要围绕文本问诊进行优化,其方法在真实医院场景中的实际作用和应用边界还需要进一步讨论。


第六组
第一位报告人:【陈泉】
报告题目:【AlphaTrans:一种面向代码仓库级代码翻译与验证的神经符号组合方法】
点评老师的意见与建议:
1、实验对象规模有限,类、方法和调用边数量偏中小,尚不足以充分证明仓库级方法的可扩展性。
2、程序转换并非简单预处理,其核心是构建更易翻译和验证的中间表示,即面向任务的IR。
3、Schema切分降低了翻译复杂度,但可能削弱语义、依赖和跨片段关系,论文对此挑战讨论不足。


第二位报告人:【单宇宸】
报告题目:【基于 SYSSPEC 的生成式文件系统实践】
点评老师的意见与建议:
1、汇报的清晰度值得肯定,但需要更明确地说明补丁具有合并机制而非简单叠加,帮助观众抓住重点。
2、文章缺乏对大模型生成代码的闭环验证机制,实际上通过反复校验反馈可以很大程度上缓解幻觉问题,说幻觉问题在提示词工程中无法解决有点绝对了。
3、该研究将形式化验证作为核心,作者可能为投 FAST 会议而刻意选择的文件系统场景。


第三位报告人:【黄志豪】
报告题目:【非标准汇点的重要性:一种用于嵌入式固件漏洞检测的全面高效污点分析框架】
点评老师的意见与建议:
1、双向污点分析方法贴合选题,突破传统前向分析路径爆炸的短板,结合后向过滤与跨边界路径生成,逻辑严谨,显著提升检测效率。
2、样本选取范围偏窄,多数为路由器固件且VxWorks仅来自TP-Link,外部效度不足,后续需扩展设备类型与厂商。
3、创新性引入SinkLens非标准汇聚点识别,优化了传统方法依赖函数名匹配的漏洞,为同类研究提供了新思路。


第四位报告人:【王嘉璐】
报告题目:【多权威的注册属性基加密】
点评老师的意见与建议:
1、汇报中对核心机制的解释仍偏理论化,缺少贴近实际的类比和案例支撑,导致同学们难以把握方案具体创新点和方案构造方式。
2、应用场景介绍不够充分,未能说明方案适合哪些跨域协同场景,也未清晰介绍实际价值问题。
3、文章方案的效率优势还需进一步实践测试,尤其应回应密钥生成、更新、加密和解密开销在实际应用中是否可接受、可部署。

第七组
第一位报告人:【李国瑞】
报告题目:【区块链批量订单公平系统中的抢先交易风险】
点评老师的意见与建议:
1、文章实际没有讨论攻击方法的边界条件是什么,攻击的代价是什么?这个问题可以作为后续继续研究的一个点,否则文章方法未必有多少实际应用意义。
2、PPT是做的比较认真,比较好的。在背景介绍部分可以再讲一些实际生活中的例子来介绍区块链或区块链上的问题。
3、文章没有分析防御措施,对系统的吞吐量,确认延迟的影响等没有讨论,效率和安全怎么来折中权衡。


第二位报告人:【韦玉娟】
报告题目:【通过纯合成数据缓解检索增强生成(RAG)中的隐私问题】
点评老师的意见与建议:
1、大模型合成与 agent 方法不确定性强,通用模型在医疗数据集效果待验证,需控制实验随机性,数据集是不是专门调过?
2、缺乏隐私度量与形式化理论,建议补齐安全短板,引入差分隐私等方法,做严格量化与离线检测。
3、 这篇技术是大模型进行评判的,隐私保护问题缺乏传统方法对比,有点像数据脱敏一样,可探索差分隐私等技术,更多强调创新性

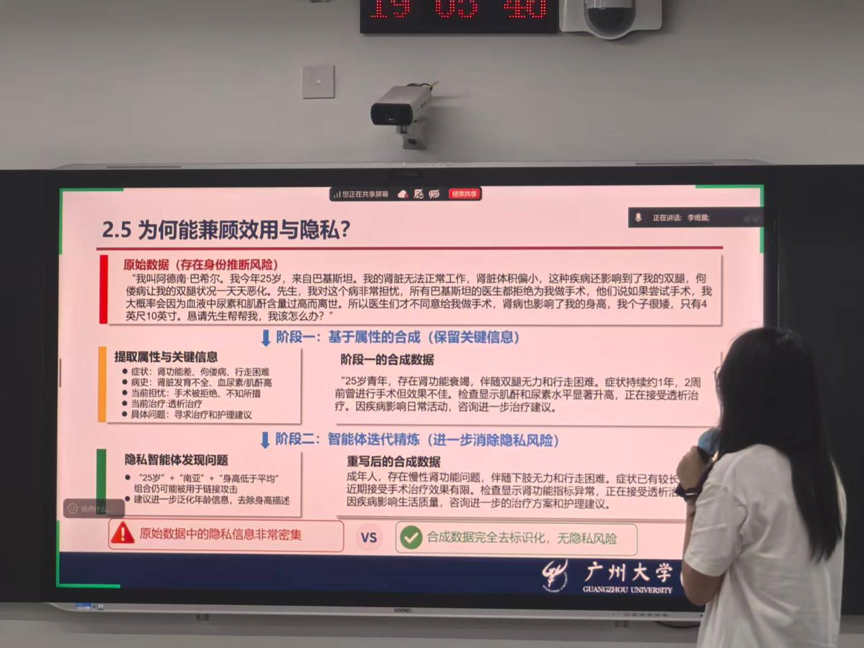
第三位报告人:【黄子杰】
报告题目:【MnemoDyn:从4万个 fMRI 序列中学习静息态动力学】
点评老师的意见与建议:
1、汇报中应补充 fMRI 脑信号分析的传统方法、Transformer 方法和扩散模型方法。
2、当前模型主要基于 450 个脑区级别的 fMRI 数据,空间分辨率较粗,难以定位海马体萎缩等微小病灶。
3、模型目前更适合性别、认知特征、轻度认知障碍等边界相对清晰的任务,复杂疾病诊断和个体化解释能力有限。


第四位报告人:【张济民】
报告题目:【面向智能电网负荷预测的隐私保护协同拆分学习框架】
点评老师的意见与建议:
1、看论文不应只看他的优点,同时也要理性看待里面的缺陷和不足
2、论文的实验结果实在GPU 仿真环境下得到的,没有落地真实场景验证,结果不够说服力
3、论文对模型的鲁棒性和对抗攻击这方面可能考虑的比较少,用户完全可以提供错误数据,进行模型投毒。


第八组
第一位报告人:【李小鑫】
报告题目:【基于标准化流的网络流量可解释异常检测】
点评老师的意见与建议:
1、关注正常流量训练数据的质量,避免异常样本混入后影响模型对正常分布的学习
2、讨论模型在不同网络环境中的泛化能力,尤其是跨数据集部署时的分布漂移问题。
3、说明 log-likelihood 阈值设置依据。。


第二位报告人:【刘瑛琪】
报告题目:【端到端开放集半监督学习的细粒度加密流量分类】
点评老师的意见与建议:
1、文章是现有模块叠加,算法原创性不足,需要更多去考虑在讲解过程突出他的核心贡献,以及和已有开放性、开放世界方法的差异;
2、建议按照论文的方法组成结构讲解,分为“双支路特征提取-能量模型未知分类-未知类自适应深度聚类”三个核心模块,不要拆得太细,方便听众抓总理解。
3、整体肯定汇报清晰度,认为同学对论文内容理解到位。


第三位报告人:【王柏涛】
报告题目:【LLAMA基于大语言模型的多反馈智能合约模糊测试框架】
点评老师的意见与建议:
1、建议更加深入的了解为什么种子生成的过程中要用大语言模型,不仅仅是为了它的一个语义理解的能力,还有更加深层次的意义。
2、对于前置工作的介绍太少了,可以更多的介绍智能合约相关的漏洞检测机制和模糊测试现有工具的情况和它们的一个工作流程。
3、对于调度算法讲解的不够透彻,论文讲到的老虎机调度算法没有完全清楚的表达出来,但是总体依旧不错。


第四位报告人:【王博文】
报告题目:【ACTaint Agent-Based Taint Analysis for Access Control Vulnerabilities in Smart Contracts】
点评老师的意见与建议:
1、有没有想法改成通用的业务逻辑漏洞检测的方案?你觉得文章最大的创新点在哪?
2,对你自己的启发点是什么?
3,没有抓住论文的重点和中心,讲解偏离了文章的中心方向,提到的改进方向也很有偏颇,要注意论文阅读的方法。


