第215期方班学术研讨厅成功举办
2025 年12月25日 18:00-21:30,第215期方班学术研讨厅在黄埔研究生院B2栋成功举办。广州大学网络空间安全学院名誉院长方滨兴老师,主点评吴世忠老师,张彦春老师,周万雷老师,黄兴忠老师,李建新老师,王文敏老师。副点评陈艳丽老师,吴昊天老师,唐可可老师,张帆老师,欧阳典老师,张登辉老师,张鹏老师全程参与了课堂的教学,并对同学们的报告逐一进行了指导点评。同时参与的还有网络空间安全学院的部分老师,广州大学方班八期的252名学生。本次研讨厅分为七个小组进行。第一组汇报的同学有饶智创,刘道铭,余国锋,汪功铭;第二组汇报的同学有吕榕琪,刘正茂,罗炜垚,唐兴顺;第三组汇报的同学有马一冉,曾瑞,罗志松,陈嘉诺;第四组汇报的同学有姚俊豪,谢杰臻,刘逸飞,黄信凯;第五组汇报的同学有朱毅明,田梓汎,张浩天,郑仕榕;第六组汇报的同学有杭微,林思妍,梁智霖,刘婷玉;第七组汇报的同学有张展鹏,刘汇聪,农圆圆,邓宇航。
第一组
第一位报告人:【饶智创】
报告题目:【用于交通流量预测的自监督学习时空纠缠转换器】
点评老师的意见与建议:
1、对于本文最大的创新点,关于时空纠缠性其实可以理解为时空依赖性的一个特殊情况,本文对这个时空纠缠性问题的提出,只是解释了这个现象,但是并没有具体的理论只是去证明。
2、另外对于捕捉时空纠缠性的方法上,其实只是利用的掩码机制,让模型学会这种时空依赖性的变化并不是一个很创新的点。
3、对于第一次和第二次都是关于车流预测的论文,有没有什么收获,对于俩次的论文有没有什么不同点以及相同点。

第二位报告人:【刘道铭】
报告题目:【MiniCache:大语言模型深维度的KV缓存压缩】
点评老师的意见与建议:
1、需深入理解论文中的核心方法,如跨层压缩机制、更高比例合并、多维融合、自适应调节等,避免仅停留在表面描述
2、避免直接翻译并拷贝论文原文的表述,应基于自身理解进行凝练和重新组织
3、可以参考研讨厅214期姜同学讲解类似技术文章的思路,了解如何基于实验现象进行方法论证,并启发自己的总结与展望


第三位报告人:【余国锋】
报告题目:【深度伪造语音基准测试】
点评老师的意见与建议:
1、建议未来的基准测试应当建立动态演进机制,定期吸纳来自真实诈骗案例、新型生成工具(如豆包语音模型语音合成)以及跨语言环境的语音样本,构建 一个持续生长的“活体”测试集。
2、语音基准测不能仅依赖EER、AUC等传统信号层面的指标,而应系统性地融入人类听觉感知的评判标准。设立“感知-信号”双轨评估框架,量化模型对频谱伪影的捕捉能力。


第四位报告人:【汪功铭】
报告题目:【FedAS:弥合个性化联邦学习中的不⼀致性】
点评老师的意见与建议:
1、询问参数对齐是否会削弱联邦学习整体效果,如果强行让新参数向旧参数靠拢,可能会导致梯度步伐变小,限制模型的更新幅度和效率。
2、在讲解Fisher矩阵时,不要过于纠结数学公式的推导,该指标的物理含义以及如何使用矩阵。
3、建议增加更多数据集验证;如果数据差异极大(如图像 vs 语音),根本就不应该强行联邦。
1、论文逻辑是不能喜新厌旧,要向老模型靠拢,如果站在创新的角度,这可能被视为因循守旧,限制了模型探索最优解的能力 。
2、论文假设 Fisher矩阵获取信息值时曲率大信息值就高有逻辑上的问题;现实中掉队常因通信延迟导致没被讨论;为了计算Fisher矩阵反而增加了端侧算力负担,可能人为制造了更多掉队者。


第二组
第一位报告人:【吕榕琪】
报告题目:【CTINEXUS:使用大语言模型自动构建网络威胁情报知识图谱】
点评老师的意见与建议:
1、制作的PPT内容充实,动画效果好,布局也非常合理,有小结的回顾也有总结与分析,整体的汇报效果非常好,讲的很清晰。
2、在描述论文整体框架的时候,即每个阶段或者方法做了什么要先简单地过一遍,包括各方法之间有什么关联,给大家讲清楚了大家就知道这篇论文究竟做了什么,重点是突出论文的主题。
3、在汇报的时候可以加上一些和现有研究的对比,从而突出这篇文章的特点。另外一方面这篇文章提到的方法是具有依赖性的,这一点要强调,不去强调的话大家可能比较难发现问题。


第二位报告人:【刘正茂】
报告题目:【基于BERT到CNN-BiLSTM知识蒸馏的车载网络高效入侵检测】
点评老师的意见与建议:
1、第一章应该多一个各种协议攻击的事例和方式。
2、数据集的各种形式,以及组成要进行介绍。
3、第二章中对于知识蒸馏的理解不够充分,还需精炼。


第三位报告人:【罗炜垚】
报告题目:【基于eBPF的内核级隐藏rootkit检测】
点评老师的意见与建议:
1、技术方法创新性:老师认为采用eBPF技术检测内核级rootkit具有前瞻性,有效应对系统调用劫持和DKOM攻击,但建议进一步探讨eBPF在动态内核安全监控中的通用性与局限性。
2、实验验证全面性:实验覆盖多种主流rootkit工具包,功能性测试充分,但老师建议增加真实云环境下的攻击模拟,以提升检测机制在复杂场景中的鲁棒性。
3、性能优化空间:HKRD在CPU和内存使用上优于传统工具,但老师指出复杂场景下仍存在开销,建议优化算法以减少性能波动,并嵌入长期稳定性验证。
4、实际应用拓展:研究具较高实用价值,老师推荐探索HKRD在多云平台中的部署方案,并加强与其他安全组件的集成,以提升整体防御体系的协同效率。


第四位报告人:【唐兴顺】
报告题目:【COUNTMAMBA:一种基于粗粒度表示与细粒度预测的通用网站指纹攻击方法】
点评老师的意见与建议:
1、部分的概念的讲解顺序需要调整,让逻辑更通顺。
2、需要补充框架的威胁模型。
3、资源加载的顺序和间隔是固定的,如果网络不是十分可靠的话,导致数据包输入的时候存在丢包,那会不会影响产出的结果?


第三组
第一位报告人:【马一冉】
报告题目:【动态车辆信誉共识:用区块链算法增强车联网通信】
提问老师意见:
1、系统框架这一页没有串联起来,你能讲一下从车进入这个范围在区块链网络和通信网络之间的运行流程吗?
2、针对动态一致性阈值计算过程当中的共识延迟指标为什么是网络变慢而提高阈值呢?
3、
在信誉投票过程当中,为什么说通过根据节点信誉分给不同权重能降低延迟呢,如果卡在高信誉节点不就会拖慢投票进度吗?


第二位报告人:【曾瑞】
报告题目:【VulSCA:一种精确分析 C/C++ 供应链漏洞的社区级 SCA 方法】
点评老师的意见与建议:
1、汇报逻辑过于平铺直叙,像流水线报告。应改为问题导向,围绕“如何解决路径爆炸”等核心问题展开,解释设计动机而非单纯罗列步骤 。
2、详略失当,在非核心细节上脱稿解释过久。建议对PPT未写且不重要的细节一笔带过,避免分散听众注意力 。
3、相关工作铺垫不足,未讲清现有方法的局限。这导致难以反衬出本文的创新点及实现难点,应加强与Baseline的对比以凸显价值 。
4、核心矛盾阐述不透彻,应讲透语义社区如何在版本级分析的高误报与函数级分析的路径爆炸这两个极端间找到最佳平衡点。


第三位报告人:【罗志松】
报告题目:【GAME-RL:通过强化学习生成针对基于 API 调用检测的对抗性恶意软件样本】
点评老师的意见与建议:
1、论文重心应紧扣强化学习主题,突出创新点,避免过度侧重神经网络部分。
2、GAME-RL框架的高效性在于选择高频API作为hookedAPI,并在其后方一次性批量插入insertedAPI。
3、顶刊论文以方法严谨全面见长,顶会论文以问题新颖有趣取胜,两者均有助于提升研究水平。
方老师点评:
1、框架图未阐明设计动机,直接从实现入手,使听众难以理解其必要性。
2、关键方法,如“无操作攻击”应通过PPT等可视化方式仔细展示,而非一语带过。
3、论文自称高效,但训练采用的自回归策略仍可能导致组合爆炸,效率存在疑问。


第四位报告人:【陈嘉诺】
报告题目:【注意力驱动的免微调MLLM GUI定位】
点评老师的意见与建议:
1、这篇论文属于探索发现类论文,对于我们开展后续研究的实际意义不大
2、虽然论文方法比较简单,但其idea非常的新奇,能发出来就是好论文
3、这论文的重点是其对注意力机制的探索发现,不用批判这比较差的实际表现效果。


第四组
第一位报告人:【姚俊豪】
报告题目:【泄露密码对蜜罐密码有效性的影响】
点评老师的意见与建议:
1、溯源部分可以加强,背景介绍不够充分。
2、适用场景可以详解说明,用场景来说明。
3、局限性和未来前景不够具体,可以加上自己的思考。


第二位报告人:【谢杰臻】
报告题目:【dcGuard:检测和隔离云数据中心恶意节点的整体方法】
点评老师的意见与建议:
1、这篇文章是比较工程类的,要搞清楚论文提出方法的软件基石、创新性以及相比于传统方法的优势。
2、论文比较长,理论分析部分要讲清楚,公式是怎么推导的,为什么能这样化简。

第三位报告人:【刘逸飞】
报告题目:【SketchFeature:面向安全感知数据平面的高质量流级特征提取器】
点评老师的意见与建议:
1、对关键技术实现与开销分析不足。需明确草图虚拟化具体实现机制、引入的元数据与硬件开销,并分析布隆过滤器空间与性能的权衡点。
2、研究背景与逻辑链条铺垫不充分。应强化“面向安全感知数据平面”的背景,并清晰阐述为何“高质量”特征提取依赖于解决所述两个关键问题。
3、问题界定与题目表述可更精确。“高质量”为主观评价,建议使用如“资源受限条件下”等更客观的术语,使研究目标更明确。


第四位报告人:【黄信凯】
报告题目:【DecoyPot:一种基于大语言模型的Web API蜜罐系统,用于实现逼真且自适应的网络欺骗】
点评老师的意见与建议:
1、该论文开创性地融合LLM与RAG实现了API蜜罐的动态欺骗,但细节上存在学术留白,这正是本研究通过可复现框架与自适应算法做出增量贡献的切入点。
2、复现过程中需深度思辨每个超参数(如0.85-0.95相似度阈值)的统计意义与领域适应性,即使原文未详述,因其直接影响0.978到0.675的性能差距,暴露模型版本依赖性问题。
3、背景介绍需强化代入感:从"85%流量经API"延伸至"单条泄露可致百万损失",将抽象威胁转化为具象风险,凸显静态防御对未知参数组合攻击拦截率不足40%的核心矛盾。


第五组
第一位报告人:【朱毅明】
报告题目:【3D CAVLA:利用深度和3D上下文泛化视觉-语言-动作模型以应对未知任务】
点评老师的意见与建议:
1、 阅读论文时要客观看待论文的创新点。
2、文章比较偏工程化。


第二位报告人:【田梓汎】
报告题目:【基于大语言模型生成 API 参数安全规则以检测 API 误用】
点评老师的意见与建议:
1、API可能一个函数就会调用多个参数,同时每个参数之间也可能有相关约束。
2、仅根据API源码分散检验参数是会导致规则遗漏的,后续可以想一下怎么解决这个问题。
3、讲的挺好,有自己的理解,不过最好还是附上和第一次的对比。
方老师点评:
1、大模型很多的输出都是比较表面或者直觉性的,可以思考怎么样解决这个问题。
2、整个系统层面其实存在语义和程序实现的鸿沟,这个也是整个系统最大的缺点。


第三位报告人:【张浩天】
报告题目:【基于博弈论的无服务器计算性能优化】
点评老师的意见与建议:
1、老师指出汇报中提到 “非合作博弈建模”,但未明确博弈参与者的收益函数具体形式(如何量化 “性能 - 成本” 的收益权重)、博弈均衡点的判定标准(如延迟≤SLO 阈值且资源利用率≥80%)
2、老师认为现有实验基于同构节点集群,未考虑真实生产环境中的异构节点(不同 CPU 性能、内存容量)。
3、老师指出问题指向和研究内容没有完全对应上去,差了一点逻辑。


第四位报告人:【郑仕榕】
报告题目:【从风险到弹性:对联邦学习中数据重构攻击风险的评估和缓解】
点评老师的意见与建议:
1、汇报整体讲解的风格非常好,有按照自己的理解来讲而不是照讲PPT,但是在标题部分没有加上每个小点的节数可以改进一下。
2、现联邦学习经常出现边缘计算的场景,此时计算的硬件资源不足,计算消耗太大不一定适合这种场景,文章有没有给出具体的时间资源开销。
3、这是一篇理论性非常强的文章,写的有水平但是有一个问题没有讲清楚那就是这个可逆性损失到底是根据什么挖掘出什么关系来判断攻击风险的。


第六组
第一位报告人:【杭微】
报告题目:【PRSA:针对真实世界提示词服务的提示词窃取攻击】
点评老师的意见与建议:
1、PPT内容比较丰富,汇报比较详细,可以看出花了较长时间准备,但是汇报过程中语气比较平稳,听不出来重点。
2、提示词泄漏和提示词窃取存在一定的区别,在一开始介绍第二次汇报与第一次汇报的区别与联系时,应该重点紧扣题目,突出提示词窃取的威胁。
3、真实世界进行操作的时候会存在一定的局限性,对同一类的提示词生成功能一致性但语义不一致的提示词并不能认定攻击时有效的,后面可以再看看最新的关于提示词窃取的研究,看是否可以有提升的地方。

第二位报告人:【林思妍】
报告题目:【TRAIL:一种基于知识图谱的高级持续性威胁归因方法】
点评老师的意见与建议:
1、关于实验部分的朝鲜两个组织的误判问题,需要解释是因为同源特性导致的相似性,而非方法本身缺陷,否则可能引发对方法有效性的质疑。
2、肯定了汇报形式改进,特别是框架图与细节结合的呈现方式,这种全局-局部呼应能有效防止听众迷失。
3、肯定了该研究在APT归因难题上的创新探索,认为知识图谱与威胁情报的结合填补了系统性挖掘网络型IOC价值的空白。

第三位报告人:【梁智霖】
报告题目:【AutoPT:我们距离完全自动化的web渗透测试还有多远?】
点评老师的意见与建议:
1、总体讲的比较清楚,但是逻辑稍微有点乱,讲的内容有点琐碎。
2、文章选的挺好,但讲的时候缺乏一个规则和LLM如何进行交互的过程。
3、研究背景那里应该重点讲的是现有方法的局限性而不是特点,从现有方法的局限性分析引出本文方法会更好。


第四位报告人:【刘婷玉】
报告题目:【PentestGPT:评估和利用用于自动化渗透测试的大型语言模型】
点评老师的意见与建议:
1、ptt解决复杂攻击链中策略固定的问题,是在约束LLM的搜索空间还是在增强它的推理能力,他更偏向哪一点?
2、整体汇报很流畅,ppt做的也很精美,但细节信息过多,应进行必要的简化,整个自动化渗透流程应该梳理清楚。
3、讲的很好,文章核心是怎么让人工智能也能像人一样思考,如何在渗透测试中缓解幻觉问题和上下文及隧道视觉。


第七组
第一位报告人:【张展鹏】
报告题目:【脑图对比学习的因果不变性感知增强方法】
点评老师的意见与建议:
1、在讲述核心概念“不变子图”时,缺乏对先导性定义的讲解,建议后续研究可以结合线性代数中的正交、特征向量等概念,做进一步的研究。
2、文章实验节点表达向量的训练未针对本任务进行,其通用性未证明。
3、实验设计存在优化空间,如缺少与不强调不变性的基础图神经网络模型进行对比,以更直观地体现方法在提取“不变性”特征上的优势。
方老师点评:
1、本文实际仅通过统计模型揭示关联,但论文混淆相关与因果。需证明模型因果图与真实脑结构一致,否则结论可信度存疑。
2、子图提取易产生碎片化信息,而脑图具有整体性。当前方法可能破坏脑网络的连贯结构,影响模型适配与解释性。


第二位报告人:【刘汇聪】
报告题目:【Unify ML4TSP: 从简化的学习与搜索设计空间中提取 TSP 及更广阔组合优化的方法论原则】
点评老师的意见与建议:
1、该论文提出的方法与单纯使用求解器获得最优解相比,其优势体现在哪里?
2、未来研究可从两条线展开:一是从考虑它属于 np 难的问题思考;二是探索与进化算法的混合范式。
3、该论文采用蒙特卡罗树搜索(MCTS),后续可尝试将 MCTS 与进化算法等范式融合,这仍是一片值得挖掘的空间。

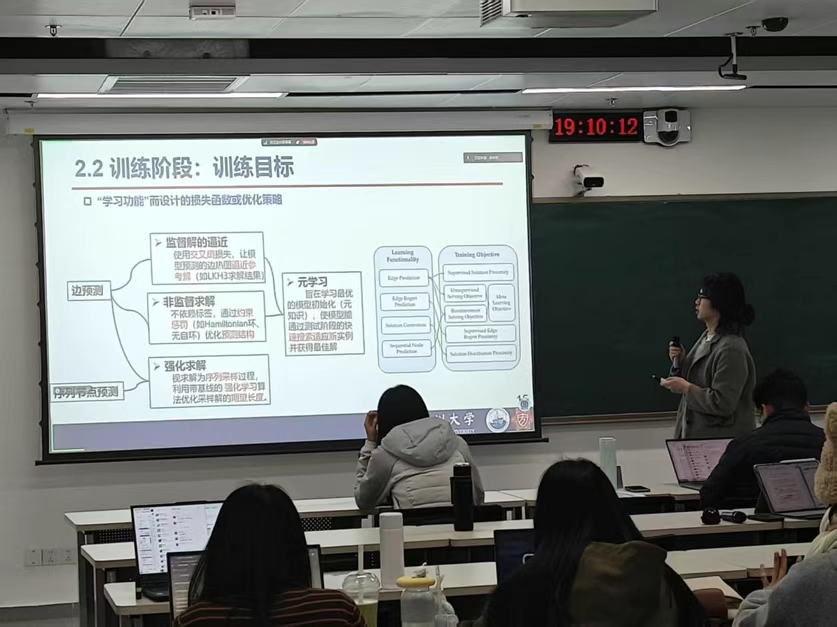
第三位报告人:【农圆圆】
报告题目:【迈向更好的对齐:利用强化学习在稀疏奖励下训练扩散模型】
点评老师的意见与建议:
1、关键参数t的取值逻辑、与分支采样次数N的关联需明确;需验证去噪步骤增多时对结果的影响。 PPT图文并茂,汇报整体表现较好。
2、需明确该方法在稀疏奖励RL的相关工作分类中是否为最新、最优,需补充该领域相关研究对比。
3、对相对传统pathORAM算法性能提升问题原理进行详细解释。现有对齐度可探索其他参考指标;模型对提示词依赖性强,可结合图像理解方法将图像转化为文本后与提示词比对相似度,内部优化提示词以改进结果。


第四位报告人:【邓宇航】
报告题目:【GENIUS:一种通用的多模态生成式检索框架】
点评老师的意见与建议:
1、论文与社交网络的联系选题有趣,但是讲的过于平淡,可以讲的更有趣一点。
2、看论文时要重点注意论文的贡献部分,一般在第一段的最后一句。
3、要从宏观上介绍文章的整体架构,从整体到部分。


