第212期方班学术研讨厅成功举办
2025 年12月4日 18:00-21:30,第212期方班学术研讨厅在黄埔研究生院B2栋成功举办。广州大学网络空间安全学院名誉院长方滨兴老师,主点评云晓春老师、陆军老师、周方雷老师、徐贯东老师、张宏科老师、李晓明老师、俞能海老师。副点评陈艳利老师、吴昊天老师、唐可可老师、张帆老师、欧阳典老师、张登辉老师、张鹏老师全程参与了课堂的教学,并对同学们的报告逐一进行了指导点评。同时参与的还有相关学院的部分老师。
本次研讨厅分为七个小组进行。教学 3 班汇报的同学有黄章杰、游俊爽、肖祥旗、李秉伦;教学 4 班汇报的同学有单宇宸、陈家豪、蹇皓杰、罗凯文;教学 5 班汇报的同学有钟林、刘涛、程晋业、关胜圆;教学 6 班汇报的同学有郝怡琛、陈泉、刘菁润、刘思成;教学 7 班汇报的同学有吴坚伟、张飞帆、金善玮、何建辉;教学 8 班汇报的同学有陈鸿烨、郑焕杰、江晓艺、卢芳;教学 9 班汇报的同学有李国瑞、张仁杰、郑斌、王茂碧。
第一组
第一位报告人:【黄章杰】
报告题目:【基于报文长度模式深度语义分析的隧道洪泛流量检测】
点评老师的意见与建议:
1、准备汇报前,尽量去做论文方法的复现
2、对论文的理解比较表面,没有思考过为什么要这样做
3、探讨Exosphere是部署在隧道网关上还是边界路由器上


第二位报告人:【游俊爽】
报告题目:【针对大型语言模型的弱到强越狱】
点评老师的意见与建议:
1、明确论文核心创新点,优化内容表述的通俗性,可从 “小模型破坏大模型” 方向深化研究。
2、关键发现拆分页面并结合通俗例子讲解,实验需补充 a 值公式、作用及突出数据标注。
3、补充实验复现支撑研究,强化理论分析(如边界分析),避免仅研讨文章而无实证支撑。


第三位报告人:【肖祥旗】
报告题目:【对多模态学习发起后门攻击】
点评老师的意见与建议:
1、虽然BAGS的方法可以在训练前期就能选出贡献度最高的样本,但梯度迭代会不会消耗更多的计算开销
2、梯度迭代的过程中有没有考虑过局部最优的问题
3、实验部分的ppt可以优化一下合并一些部分一起讲
4、可以对正常主导模态不等于后门主导模态的问题进行刨根问底

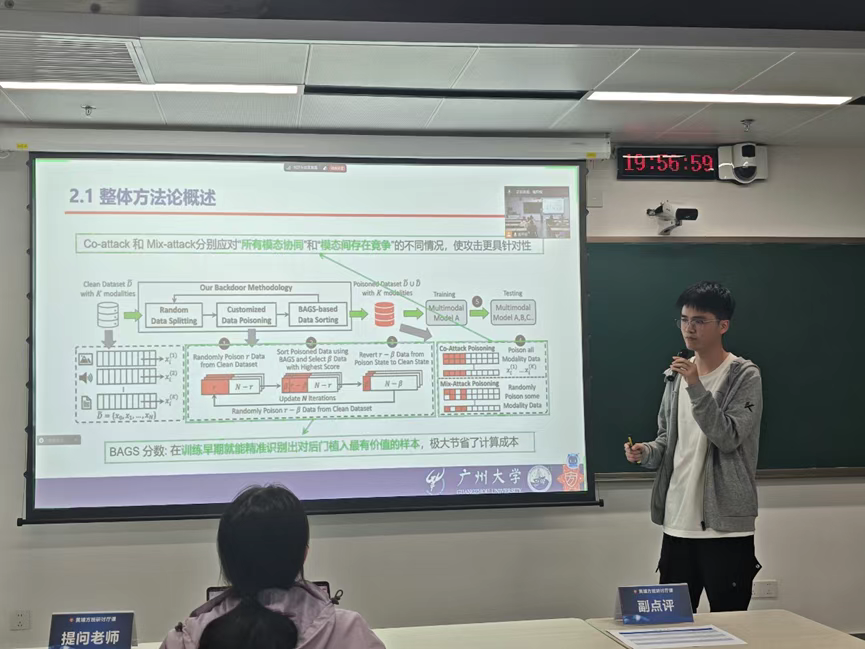
第四位报告人:【李秉伦】
报告题目:【Graphiti: 让安全图计算更具可拓展性】
点评老师的意见与建议:
1、这几次汇报都是关于图计算的,PPT里可以添加与上一次的对比,再结合自己做的工作做一个完整的对比。
2、算法部分讲的太底层了,不方便大家理解。建议先从整体框架进行讲解,再对涉及的模块进行详细讲解,最后再进行一次总结。
3、背景应先概括已有协同图/安全图相关研究,凝练论文中提到的少量相关工作及其不足(如泄露结构、效率低、难扩展),再指出这些问题并引出本文通过隐藏拓扑与安全消息传递的改进方案。
方老师点评:
1、读一篇论文时,首先要把握作者提出方法的核心思想,弄清楚他为什么要这样设计、试图解决什么问题。在理解原理之后,要进一步分析作者方案背后的隐含假设与潜在不足,例如是否可能出现数据溢出、是否仅适用于静态图、对大规模数据是否有性能瓶颈,以及在真实系统中是否易于部署。只有理解“作者做了什么”与“为什么这样做”,再看到“还能如何改进”,才能真正建立自己的研究视角,而不仅仅停留在复述论文内容。
2、弄清楚作者为什么想要将图转化为列表,然后为什么需要有三种排序方式,是为了解决什么问题。作者的方案与之前的相比,为什么就可以节省通信和开销,其实是将大部分排序计算放在了初始化阶段。而在初始化阶段中作者引入了可信第三方,这样做是否合理,都是值得去思考的。


第二组
第一位报告人:【单宇宸】
报告题目:【在分布式文件系统中结合缓冲IO与直接IO】
点评老师的意见与建议:
1.可以把页缓存的过程通过动画和类比的方式进行讲述,观众的理解可能比现在这样文字对比要好。
2.对于论文中提到的摩尔定律等定义,描述的时候要更严谨一点。
3.研究背景的小结不够明显,应该还要加一些限制条件,把优势和动机单独捡出来。
4.论文在实验这一块只给了结果,对结果的分析不足,为什么会有这样的情况可能还需要更多的说明。


第二位报告人:【陈家豪】
报告题目:【通过预测性社区划分实现多层次图表示学习】
点评老师的意见与建议:
1、通过找社区生成次要全局图和主要全局图,怎么能说明他提高了精度?
2、是否存在多层级的图表示学习方法,图表示学习方法当中是否有基于社区的划分方法?
3、讲论文流程之前要先讲主要思想,为什么要划分在线和离线?有没有阈值的问题?增加社区的划分会不会增加复杂度?


第三位报告人:【蹇皓杰】
报告题目:【KernelGPT:基于大型语言模型的增强型内核模糊测试】
点评老师的意见与建议:
1、老师们肯定了我真正读懂了文献,并对我的演讲和分享给予了表扬。
2、李老师对论文的实现细节进行了点评,剖析了“最大迭代次数”设置规律。
3、吴老师对论文的不足提出了意见,说到LLM的可扩展性可以再进一步分析。
4、陆老师教学生学会要思考论文是否提出了的科学性问题,例如为什么LLM可以理解人类的语言等,以及提心同学们学会反思科学性问题。


第四位报告人:【罗凯文】
报告题目:【一种用于跨网络加密的DoH流量检测和隧道识别的混合深度学习框架】
点评老师的意见与建议:
1、背景介绍中DoH流量的特征有哪些,比如一个DoH流量是一个大包,然后后面跟随许多个小包,因此使用CNN+BiGRU可以捕获这种特征,这样介绍更能够从动机出发讲好这篇论文的背景
2、介绍DoH的背景知识时可以先介绍HTTP协议的结构原理,不要太过泛化。
3、深度学习为什么好?多问问自己这样的问题,多问几个为什么


第三组
第一位报告人:【钟林】
报告题目:【人机反馈循环如何重塑人类的感知、情感与社会判断】
点评老师的意见与建议:
1、选题偏社会学领域,研究方法与计算机科学关联度不足;实验验证相对简单,需加强在计算领域的专业深度和严谨性。
2、建议从社会学背景转向计算领域,并对“认知偏见”给出形式化的、计算领域的精确定义。
3、探讨题目中“重塑”一词的准确性,考虑“改变”是否更为贴切,以更精确地表达研究的发生机制。
4、研究深层思考: 需进一步探讨人类固有偏见在人机反馈循环中的作用,以及模型如何处理和利用这些原生偏见。


第二位报告人:【刘涛】
报告题目:【G-Refer:Graph Retrieval-Augmented Large Language Model for Explainable Recommendation Explainable Recommendation】
点评老师的意见与建议:
1、方法部分可以花费更多的时间丰富,适当举出例子
2、要突出GNN如何检索出Prompt给LLM的
3、论文中检索内容只设计节点和路径,是否可以考虑子图的情况?


第三位报告人:【程晋业】
报告题目:【A-Mem:面向 LLM 智能体的自主记忆系统】
点评老师的意见与建议:
1、核心方法讲解不充分,NODE 构建形式、Link 生成逻辑等关键细节未拆解
2、相关工作阐述不足,现有方法的四个局限性缺乏证据支撑,自身解决方案不明确。
3、未厘清智能体记忆与环境交互、行动反馈的关联,NODE 标签与属性的界定模糊。
方老师点评:
1. 该系统是嵌入式能动记忆系统,核心是通过持续对话整理历史知识,整体工作流为循环迭代的检索与推理过程。
2. 技术架构的存在多处缺陷:一是记忆演化修改不可逆会丢失历史细节、二是过度依赖大模型易出现逻辑漂移、成本高。


第四位报告人:【关胜圆】
报告题目:【CODESYNC:大规模同步大型语言模型与动态代码演进】
点评老师的意见与建议:
1、该研究聚焦的动态代码演进同步任务,现有解决方案成熟度待考。核心争议在于需明确:是 LLM 适配 API 动态变化,还是模型主导 API 演进的双向作用逻辑。
2、该论文的技术深度与创新方法论不足,未满足方班汇报对技术性论文的核心要求,更适合作为研究视角分享,而非技术性成果汇报素材。
3、论文选题极具创新性,精准捕捉新研究问题。建议构建专属 benchmark 与科学数据收集体系,后续深入研究具备顶刊发表潜力。


第四组
第一位报告人:【郝怡琛】
报告题目:【基于HCache的LLM服务快速状态恢复】
点评老师的意见与建议:
1、缺少了针对HCache的时空复杂度的理论分析,需要有具体的公式作为支撑
2、如果只有显存-SSD这样的两级存储架构,去掉中间作为缓存DRAM,将对隐藏状态的保存产生性能影响
3、关于两个挑战的解决方案,在实验中体现在消融实验部分


第二位报告人:【陈泉】
报告题目:【Starburst:一种适用于混合云的成本意识调度器】
点评老师的意见与建议:
1、论文说到JCT与云成本的平衡,为了达到这个目标,论文是怎么做的?怎么样才算是一个JCT与云成本的好的平衡呢?
2、缺少了相关工作的介绍,可以进行补充,缺少对建模部分的介绍,论文到底是怎么从现有数据出挖掘相关信息进而进行相关问题建模的,启发式方法是否足够鲁棒,实验分析要探讨优缺点
3、No Wait和Constant Wait介绍不够清晰,对于给出的例子应该再详细介绍一下,这是一个直观的论文idea的体现;集群的概念,集群发挥了什么作用;ppt文字略多


第三位报告人:【刘菁润】
报告题目:【基于分层深度强化学习的虚拟网络嵌入联合准入控制与资源分配】
点评老师的意见与建议:
1、论文上下层agent间缺乏明确的信息传递与协同机制,更多是松散串联,尚未体现分层强化学习应有的结构优势和性能互补,整体创新性和理论深度偏弱。
2、汇报中未系统梳理该方向的经典与SOTA方案,缺少充分对比与分析,难以说明本方法在接纳率、收益或复杂度等关键指标上优于现有工作,研究定位不够清晰。
3、论文方法在模型设计上主要是将GNN、PPO等既有技术简单叠加,缺少围绕VNE关键难点的独到机制与理论支撑,建议进一步凝练核心贡献,给出更有说服力的选题理由。


第四位报告人:【刘思成】
报告题目:【Aligning Logits Generatively for Principled Black-Box Knowledge Distillation】
点评老师的意见与建议:
1、实验指标是什么?对于这种蒸馏来说,教师模型与学生模型之间的差异在多少是可以接受的?有没有公认的蒸馏的成功的标准?
2、没有上一次报告清楚,对于教师模型和学生模型得更多介绍清楚,再加两次报告的连接,可以说对论文的质疑,为什么复现结果无效
3、整体把握很好


第五组
第一位报告人:【吴坚伟】
报告题目:【一种基于网络-控制-物理跨域协同的工业无线控制系统综合安全体系架构】
1. 提问老师提问白名单是基于物理组件的安全范围来决定的,正常离心机转速是1-5k,如果攻击者利用白名单的话,攻击者将转速提到2k,那是不是也在合理范围内。
2. 论文的白名单是之前有的,还是重新提出来的?


第二位报告人:【张飞帆】
报告题目:【CAMP: 针对DNS的组合放大攻击】
点评老师的意见与建议:
1、针对组合攻击中探测攻击的机制来说, 现阶段有些协议的漏洞有些已经失效, 后续需要探索出更新更好的攻击方法, 但是此攻击思路可以借鉴.
2、针对仅进行二维组合测试的局限性,需更明确地阐述“二维是机制验证基石、三维是上限展示”的科学论证逻辑.
3、对CAMP攻击流量特征的分析略显单薄, 建议深入探讨该攻击在混合正常大流量背景下的检测难度与逃逸机制.


第三位报告人:【金善玮】
报告题目:【基于零信任网络访问控制模型缓解高级持续性威胁(APT)攻击】
点评老师的意见与建议:
1. 讲解文章的动机部分时,可以将文章提出要解决的两个问题与零信任方案的不足相对应去讲,不一定要将论文中给出的所有不足点都一一写上。
2. 现在可以用欺骗防御的方法来识别和阻断APT攻击,可能在最开始就进行阻断,它与文章中的方案是一个正交的关系,日后可以结合两个课题一块进行研究。
3.文章是对APT攻击的一个改进,很多时候APT攻击不仅仅是看正确率,还是要看时效性(效率),要注重时效性方面的研究。

第四位报告人:【何建辉】
报告题目:【Magnifier: 基于轻量级流量指纹的网络接入检测】
点评老师的意见与建议:
1、Magnifier 的目的不是覆盖所有设备,而是补充传统方法无法区分品牌/型号的空缺。
2、论文说要提取系统级域名,但 App 域名如何过滤?对不同设备的域名噪声怎么处理?论文没有很明确写出来。
3、方法本身并不是从零开始的突破,更多是把域名树、蒸馏、阈值匹配组合成一个实用系统。


第六组
第一位报告人:【陈鸿烨】
报告题目:【道路网络中大规模出行查询的全局最优出行规划】
点评老师的意见与建议:
1、PPT里面虽然用动画举了一个例子,但是动作幅度较小不易看出,可以做得更好一些。
2、论文假设可获取全局信息,却未与经典动态规划等全局优化方法对比,且仅声明逼近最优,但未通过实验量化其解与理论最优解的差距。
3、全局出行信息获取在实际中难以实现,且未考虑用户对绕行等规划结果的接受度,模型预设过于理想化。


第二位报告人:【郑焕杰】
报告题目:【用于可扩展推荐的线性时间图神经网络】
点评老师的意见与建议:
1、先不考虑实验结果,我们需要认真思考“为什么能用PPNP不动点方程来实现多层迭代聚合的效果”,本质上是空间换时间的思想。
2、除了作者提出的这种模型,其他模型(比如MF)他的工作原理是什么,复杂度的计算都需要我们认真去学习思考。
方老师点评:
1、随机邻居采样的花销较大,因为采样结果形状不规则,难以利用 GPU 张量核心的并行优势,算力利用率低。我们不应忽视这种花销。
2、GNN本质上是路径依赖的,因为节点表示由 “多跳邻居信息聚合” 生成,而信息传播的路径直接决定了聚合的内容,进而影响最终结果。
3、讲的时候不要拘泥于论文中复杂的公式,演讲者需要把论文中最核心的部分用最通俗易懂的话讲出来,帮助观众理解。


第三位报告人:【江晓艺】
报告题目:【一种紧凑且精确的用于估计大范围集合差基数的Sketch】
点评老师的意见与建议:
1、论文其实是一种类似区间估计的方法,那么置信区间是一个比较重要的因素,可以对于置信区间进行探讨。
2、在讲解论文工作时,比如Sketch这个结构时,可以结合一个具体的例子进行讲解,便于听众理解。
3、相关工作可以不用讲地那么详细,时间有限要尽快进入主题,可以列个表格对比不同工作的优缺点。


第四位报告人:【卢芳】
报告题目:【仅使用交集特征即可学习知识图谱知识】
点评老师的意见与建议:
1.从有向图向无向图转换会不会更改它的语义信息?
2.在转换中会不会增大图的大小?在转换关系时,边是怎么考虑的?只用交集特征是不是不够?
3.ppt做的很好。没有三元组的话,剩下的都做不了。我说明一下为什么这个方法有效。
4.讲的很清楚。关于邻域,具体是怎么定义的呢?r的邻域里面有什么,只有边吗?


第七组
第一位报告人:【李国瑞】
报告题目:【zkGPT:LLM推理的高效非交互式零知识证明框架】
点评老师的意见与建议:
1、提问老师:用zkp为LLM提供证明时,会采用量化技术,会导致与原本的推理有偏差。
2、副点评老师:文章本身对每个技术实现方法和安全分析讨论不太充分。
3、主点评老师:文章主要为了验证已有的zkp对LLM证明是否可行,模型采用的是比较旧和小的GPT-2模型。
方老师点评:
1、零知识证明的密码学技术确实很难讲,有搞懂文章里很细节的东西,讲的很不错了
2、可以从如何使LLM的计算过程适配零知识证明,以及结合中会出现的问题来梳理文章汇报逻辑和思考之后能做的研究方向。


第二位报告人:【张仁杰】
报告题目:【基于RLWE同态加密中的双层数据打包技术用于安全联邦学习】
点评老师的意见与建议:
1、在总述中提到了可以减少密文数量,但在后续介绍中没有提及是怎么做到的,在讲解PPT时需要前后对照清楚,把前文中提出的问题、做出的贡献在后面讲解清楚。
2、介绍的两种联邦学习方法不能只是按照论文依次介绍,汇报不是做论文的复读机,需要加上自己的理解,两种方法有什么异同、那种方法更好、为什么更好,这些都要讲清楚。
3、有些场景对机器学习的无损要求很高,比如像医疗和金融领域。但这篇论文的方法真的做到了无损吗,或者说能满足这些领域的无损要求吗?这些问题最好在看论文的时候思考清楚。
4、这篇论文只是理论上的研究,现在有没有联邦学习采用了这个方法呢,这些需要调研。


第三位报告人:【郑斌】
报告题目:【Multi-ARCL:面向加密流量分类的多模态自适应中继分布式持续学习】
点评老师的意见与建议:
1. 先证明无双面神经元再动刀,防止误剪正样本;方法须用最新数据集重跑,旧结果不能当护身符。
2. 读论文养成查数据集家谱习惯,见老数据即搜后续版本,若作者避新基准则疑其过拟合旧集。
3. 安全视角防攻击者调灰态固化后门,剪前加对抗探测揪出恶意保留神经元,再决定谁留谁剪。


第四位报告人:【王茂碧】
报告题目:【基于流微元的流量关系分析:加密恶意流量的鲁棒检测】
点评老师的意见与建议:
1、文章在创新性方面尚有提升空间,没有自己的创新性模块。介绍时对恶意流量的定义可能容易引起听众误解。
2、后续研究中可考虑将时间序列分析方法应用于流量检测领域。


